| K | 您所在的位置:网站首页 › resultset 方法 › K |
K
|
一、引言 K-近邻 (K-Nearest Neighbor) 算法,也叫 K 最近邻算法,1968年由 Cover 和 Hart 提出,是机器学习算法中比较成熟的算法之一。K-近邻算法使用的模型实际上对应于对特征空间的划分。KNN 算法不仅可以用于分类,还可以用于回归。 二、K-近邻算法内容1、概念K-近邻算法就是,先给定一个训练数据集,这个数据集中可能是某类物品的特征及分类,然后给出某个物品的特征,根据训练数据集中的各个物品的特征与这个需要判别分类的物品的“距离”远近,找出距离最近的 k 个,然后这 k 个物品中最多物品所归属的那个分类就是这个需要判别的物品所归属分类判断的结果。 2、优缺点优点: 精度高、对异常值不敏感、无数据输入假定。缺点: 计算复杂度高、空间复杂度高。3、算法的一般流程(1) 收集数据可以使用任何方法(爬虫、网络上公开的数据集等)(2) 准备数据距离计算所需要的数值,最好是结构化的数据格式(一般是用些 NumPy 矩阵或者数组这种来方便储存结构化后的数据)(3) 分析数据可以用任何方法(一般常用 Matplotlib 这个库来绘一些图,来观测数据的特征)(4) 训练算法根据训练集中给出的数据来训练出一个基本的参数模型(5) 测试算法用测试集中的特征数据输入进所生成的模型,然后记录得出的结果和本来的结果是否是相同的,以此来判断模型的准确性(好坏)。注:一般训练集和测试集都是 7:3 或者 8:2,或者 7.5:2.5。 (6) 使用算法(将算法应用到应用程序中)做一些简单的命令程序,是得可以输入某个物品的一些特征从而判定该物品的类别。三、算法实现样例(样例题出自机器学习实战)1、样例介绍(使用k-邻近算法改进约会网站的配对效果)海伦一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的人。经过一番总结,她发现曾交往过三种类型的人: 不喜欢的人 ( didntLike )魅力一般的人 ( smallDoses )极具魅力的人 ( largeDoses )海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件 datingTestSet.txt 中,每个样本数据占据一行,总共有 1000 行。海伦的样本主要包含以下 3 种特征: 每年获得的飞行常客里程数玩视频游戏所耗时间百分比每周消费的冰淇淋公升数注:datingTestSet.txt 数据集及整个算法的完整实现都在我的仓库中 https://gitcode.net/weixin_52185996/knn 2、样例算法实现(1) 准备数据所给数据集中包含分类的特征和分类标签两种算法所需的类型,为了方便计算我们将其分开并格式化为我们需要的数据格式,分别存入两个 NumPy 矩阵中: def file2matrix(filename): """ :param filename: 数据集的地址 :return: 返回一个特征集和一个分类标签集 """ with open(filename, 'r', encoding='utf-8') as f: arrayLines = f.readlines() returnMat = zeros((len(arrayLines), 3)) labelsVector = [] index = 0 for line in arrayLines: features_label = line.replace("\n", "").split('\t') returnMat[index, :] = features_label[:3] if features_label[-1] == 'largeDoses': labelsVector.append(int(3)) elif features_label[-1] == 'smallDoses': labelsVector.append(int(2)) else: labelsVector.append(int(1)) index += 1 return returnMat, labelsVector(2) 分析数据这里我们使用 Matplotlib 库来创建散点图 datingDataMat, datingDataLabels = file2matrix("datingTestSet.txt") fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0 * array(datingDataLabels), 15.0 * array(datingDataLabels)) plt.show()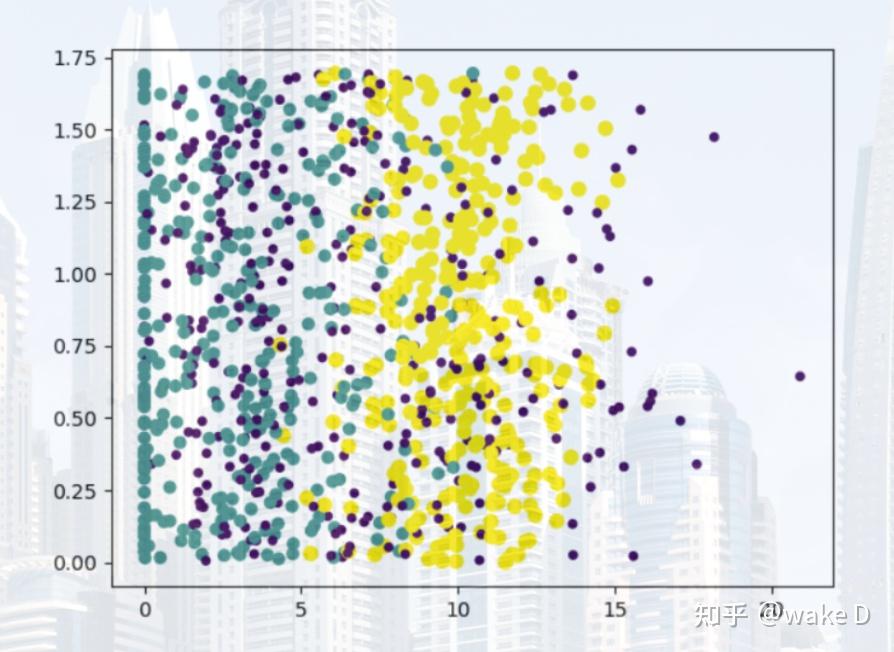 上述散点图表示 datingDataMat 矩阵的第二和第三列数据,横轴表示“玩视频游戏所耗时间百分比”,纵轴表示“每周消费的冰淇淋公升数”。不同的颜色就表示三个不同的类别。 (3) 归一化数值(模型构建)如果利用欧式距离来计算样本之间的差异的话则有: \qquad\qquad\qquad\qquad\qquad distance = \sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2} 如果 x 表示”每年获得的飞行常客里程数“、y 表示“玩视频游戏所耗时间百分比”、z 表示“每周消费的冰淇淋公升数”的话,显然同一样本的不同特征值之间的差异实在太大,比如说飞行常客的里程数对结果的影响是在太大了,因为它的数值远远大于了其他两个特征;但对海伦来说这三种特征是同样重要的,所以就需要对这三种特征分别进行归一化: \qquad\qquad\qquad\qquad\qquad\qquad\qquad newValue=\frac{(oldValue-min)}{(max-min)} 其中的 min 和 max 分别是对应的特征集中的最小和最大值。 def autoNorm(dataset): """ :param dataset: 特征集 :return: 返回经过标准归一化之后的特征集和每个特征的最大最小差值集合,和每个特征最小值的集合 """ minVals = dataset.min(0) maxVals = dataset.max(0) ranges = maxVals - minVals m = dataset.shape[0] normDataSet = dataset - tile(minVals, (m, 1)) normDataSet = normDataSet / tile(ranges, (m, 1)) return normDataSet, ranges, minVals 每列的最小值放在 minVals 中,每列的最大值放在 maxVals 中,函数返回的 ranges 和 minVals 都是为了方便算法测试才返回的,也可以选择不返回。 (4) 算法测试在这里我们用 10% 数据集中的数据来进行测试,90% 的数据用作训练输入,因为这个数据集本身就是随机排列的,所以我们为了方便可以直接去数据集的前 10% 用作测试集,后 90% 用作训练集。 def datingClassTest(): """ :return: 对算法模型进行测试,无返回值 """ testRadio = 0.1 datingDataMat, datingDataLabels = file2matrix("datingTestSet.txt") fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0 * array(datingDataLabels), 15.0 * array(datingDataLabels)) plt.show() normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] testNum = int(m*testRadio) error = 0 for i in range(testNum): predict_result = knn_study.classify0(normMat[i, :], normMat[testNum:m, :], datingDataLabels[testNum:m], 3) print(f"第{i}条数据的预测结果为: ", predict_result, ",其真实结果为: ", datingDataLabels[i]) if predict_result != datingDataLabels[i]: error += 1 print("模型预测的准确率为: ", (m - error)/m)文件 knn_study 中的 KNN 算法关键实现 def classify0(inX, dataSet, labels, K): """ :param inX: 目标特征集 :param dataSet: 特征数据集 :param labels: 对应特征数据集的标签数据集 :param K: 最近邻K的k值 :return: 返回目标特征集经过k-近邻算法所得出的分类结果 """ dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances ** 0.5 sortedDistIndices = distances.argsort() classCount = {} for i in range(K): voteIlabel = labels[sortedDistIndices[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] 这里的 knn_study.py 中的 classify0 方法就是用来计算样本之间的距离,给出算法结果的,是算法的关键部分。 (5) 算法的应用使用简单的命令来看看算法的实际运行效果 def classifyPerson(): """ :return: 算法的具体简单命令应用,无返回值 """ resultset = ['didntLike', 'smallDoses', 'largeDoses'] datingDataMat, datingDataLabels = file2matrix("datingTestSet.txt") normMat, ranges, minVals = autoNorm(datingDataMat) features = zeros(3) features[0] += float(input("请输入他(她)每年获得的飞行常客里程数: ")) features[1] += float(input("请输入他(她)玩视频游戏所耗时间百分比: ")) features[2] += float(input("请输入他(她)每周消费的冰淇淋公升数: ")) result = knn_study.classify0((features-minVals) / ranges, normMat, datingDataLabels, 3) print("该人可能属于 ", resultset[result-1], " 类型") |
【本文地址】